IT 트렌드 - Data Mesh를 통한 데이터 관리의 탈중앙화
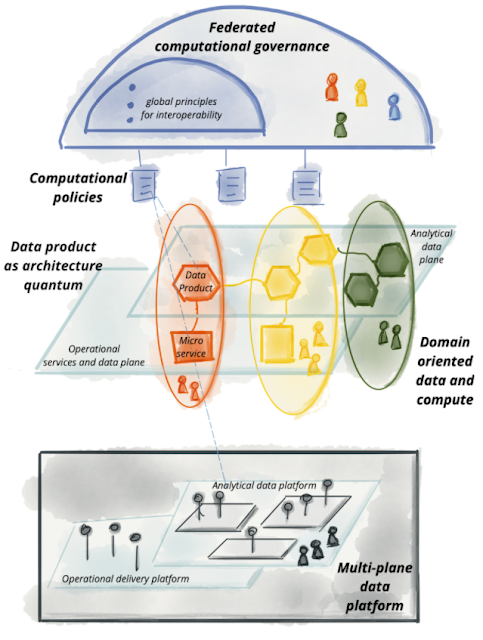
이번 글에서는 기존 DW, Data Lake 처럼 중앙 집중식으로 데이터 관리하면서 발생되는 문제들을 해결하기 위해 최근 언급되고 있는 새로운 데이터 관리 체계인 Data Mesh 개념에 대해 살표 보겠습니다. Data Mesh 출현 배경 기업은 내/외부의 데이터를 Data Warehouse 또는 Data Lake를 통해 중앙 집중적으로 수집/통합하여 비지니스 사용자들을 지원해오고 있습니다. 과거의 전통적 On-Premise와 최신 Cloud로 전환되면서 더욱 여러 종류의 Data Source들이 출현하고 있습니다. 이렇다 보니 더 많은 데이터 이동과 복잡한 ETL 작업이 수반되고 데이터의 양은 계속 증가되고 결국 어디서 무엇을 찾을 수 있는지 매우 힘들어지는 상황이 되고 있습니다. 또, DW나 Data Lake를 관리/운영 부서들이 모두 IT 중심의 부서이다 보니 각기 다른 비지니스 사용자들의 비지니스 요구 사항에 능동적으로 대응하기가 매우 어렵다는 것입니다. 그래서 전통적인 중앙 집중식 데이터 관리를 벗어나 해결하려는 고민과 시도들이 나타나게 되었습니다. Data Mesh 이란 무엇인가? 최근 Cloud 환경에서 어플리케이션을 개발할 때 기존 Monolithic 방식보다 MicroService Architecture(MSA) 방식을 채택 사례가 증가하고 있습니다. 데이터 관리에서도 이런 MSA 방식과 같이 기존 하나의 거대한 Data Repository가 아닌 각자 Domain별로 나누어서 데이터 관리 체계를 구성하는 접근 방식 나타나고 있습니다. Data Mesh는 최종 사용자가 중요한 데이터를 Data Lake나 Data Warehouse로 통합하지 않고 전문적인 데이터 팀이 개입할 필요 없이 Domain 부서에서 운영 데이터와 분석 데이터를 관리하여 쉽게 액세스할 수 있도록 하는 설계 개념입니다. Data Mesh는 데이터 관리의 병목 현상과 사일로를 줄이고 데이터 거버넌스를 희생하지 않으면서 확장성을 가능하게 하여 ...





