Data Intelligence - 지능형 기업에게 SAP Data Intelligence는 왜 필요한가?
최근의 화두인 지능형 기업으로 전환에 대한 다양한 방법과 솔루션이 등장하고 있으며 그 중요성이 이전보다 더욱 인식되고 있습니다.
간단하게 말하자면, 즉 지능형 기술인 AI, 실질적으론 머신 러닝 및 딥 러닝 기술을 적용하여 이전에는 하지 못하는 업무를 수행하거나 수동적인 업무를 자동화하여 LOB 사용자들은 본연의 업무에 집중하도록 하여 궁극적으로 기업의 경쟁 우위에 있도록 하자는 것입니다.
기업의 지능형 기술의 접근 방법으로 크게 2가지로 구분할 수 있는데, 첫째는 S/4HANA 등 Application에 사전에 빌트인 된 머신 러닝 모델을 제공하여 LOB 사용자들이 쉽게 업무에 활용할 수 있는 High Level의 접근 방식과 둘째는 사용자가 직접 기업의 다양한 데이터를 참조하여 머신 러닝 모델을 빌드하여 업무에 적용하는 Low Level 접근 방식으로 나눌 수 있을 것입니다.
이번 포스팅에서는 후자의 경우, 직접 머신 러닝 모델을 만들어서 적용하는 과정에서 좀 더 개발 과정을 간소화하고 자동화할 수 있는 방법에 대해 이야기를 나누고 싶습니다.
머신 러닝 모델은 만들기 위해서는 다양한 머신 러닝 기법과 지식이 요구됩니다. 알고리즘 선택, 하이퍼파라미터 튜닝, Feature Engineering, Feature Selection 등 머신 러닝을 공부하거나 경험해 보신 분이라면 이런 용어 및 절차에 익숙하실 것입니다.
그리고, 무엇보다도 데이터가 필요하며 당근 기본입니다. 하지만, 우리는 머신 러닝 실습, 예제, 교육 등에서 데이터를 기본적으로 전달 받기 때문에 데이터 획득 문제에 대해 그렇게 중요하게 생가하지 않고 당연하게 누군가 해 주겠지 하고 여겼습니다.
하지만, 현실은 그리 녹녹하지 않습니다. 어떤 주제에 대한 머신 러닝 시나리오에 대한 모델을 만든다고 가정해 봅시다. 데이터는 어디에 있을까요? 네, 데이터는 다양한 시스템에 존재하고 있습니다. S/4HANA, Cloud Application, BW/4HANA, EDW, DBMS, Hadoop, Data Lake, 외부 등 분산되어 존재하고 있습니다.
그런데, 실질적으로 모델을 만드는데 필요한 데이터는 어느 시스템에 존재할까요? 우리는 이것을 위해 개별 시스템 담당자에게 데이터 추출을 요청하지만, 이것도 계속적으로 요구되어 해당 시스템 담당자를 매우 곤욕스럽게 만드는 경우를 보았습니다.
머신 러닝 모델 구현 근처에 가지도 전에 우리는 한숨이 나오는 것입니다. 뭐 좀 해보려면 데이터가 어떤 시스템에 존재하지 모르겠는데요. 그런 주제에 맞는 데이터가 우리 회사에 가지고 있는지 여부도 잘 알기 힘든 상황입니다.
여러분은 머신 러닝(ML) 이니셔티브 또는 더 나은 정보 관리 중 무엇이 더 필요합니까? 미래 지향적인 회사라면 답은 둘 다여야 합니다. 그러나 이는 우선 순위의 문제인 경우가 많으며 많은 사람들이 정보 관리에 집중하기로 선택합니다.
Forrester가 전 세계 IT 의사 결정권자 178명을 대상으로 실시한 설문 조사에 따르면, 조직의 82%가 데이터 프로세스 및 워크플로의 오케스트레이션 및 자동화가 성공에 중요하다고 생각합니다. 그러나 동일한 응답자의 37%만이 이를 성공적으로 수행할 수 있다고 자신했습니다. 동시에 67%는 ML 처리 구현이 중요하다고 생각했지만 33%만이 그렇게 할 수 있다고 확신했습니다.
데이터가 ML에 공급되고 ML이 효과적인 정보 관리를 필요로 하기 때문에 과제는 불가분의 관계로 연결되어 있습니다.
AI 구축을 위한 전통적 데이터 관리의 한계
AI 기반의 업무 프로세를 위해서는 데이터 기반의 정보 관리가 기본적으로 요구되고 있습니다. 하지만, 현재의 정보 관리 접근 방식은 기술 변화를 따라가지 못하고 있습니다.

대부분의 전통적 데이터 기술은 온프레미스 데이터베이스와 상호 작용하는 온프레미스 애플리케이션의 시대를 위해 구축 및 설계되었습니다.
여기에서 목표는 데이터를 추출하여 비즈니스 인텔리전스 및 보고를 위한 데이터 웨어하우스에 로드하는 것입니다. 그 필요성은 여전히 존재하지만 우리가 관리하는 데이터와 해당 데이터에서 가치를 추출하는 방식은 근본적으로 변화하고 다양화되었습니다.
오늘날 우리는 클라우드와 온프레미스 시스템이 혼합된 구조화, 비정형 및 개체 저장소 데이터가 복잡하게 혼합되어 있으며 액세스가 API를 통해 제한되거나 표준화되지 않는 경우가 많습니다. 그 결과 데이터 스프롤, 도구 다양화 및 데이터 사일로의 복잡한 환경이 조성됩니다.
이 모든 것이 "지식에서 잃어버린 지혜를 찾는 것"과 "정보에서 잃어버린 지식을 찾는 것"을 그 어느 때보다 어렵게 만듭니다.
전통적 ML과 정보 관리가 실패하는 경우
ML과 정보 관리를 함께 사용하면 더 나은 결과를 얻을 수 있습니다. 하지만, 데이터 과학 프로젝트에서 더 많은 개선의 필요성을 요구됩니다.
- 기업의 86%는 데이터에서 훨씬 더 많은 것을 얻을 수 있어야 한다고 말합니다.
- 초기 데이터 과학 이니셔티브 10개 중 5개가 프로덕션에 도달하지 못한다고 말합니다.
- 74%는 데이터 환경이 너무 복잡하여 민첩성을 제한한다고 말합니다.
그리고 아마도 가장 중요한 사실은 기업의 2/3가 머신 러닝과 AI를 중요한 이니셔티브로 간주하는 반면, 1/3 이하만이 이러한 이니셔티을 구현할 수 있는 능력을 확신한다는 것입니다.
대다수의 기업은 이러한 이니셔티브의 중요성과 잠재적 이점을 인식하고 있습니다. 그렇다면 기업은 어떻게 데이터 과학 프로젝트에서 확신을 가질 수 있을까요?
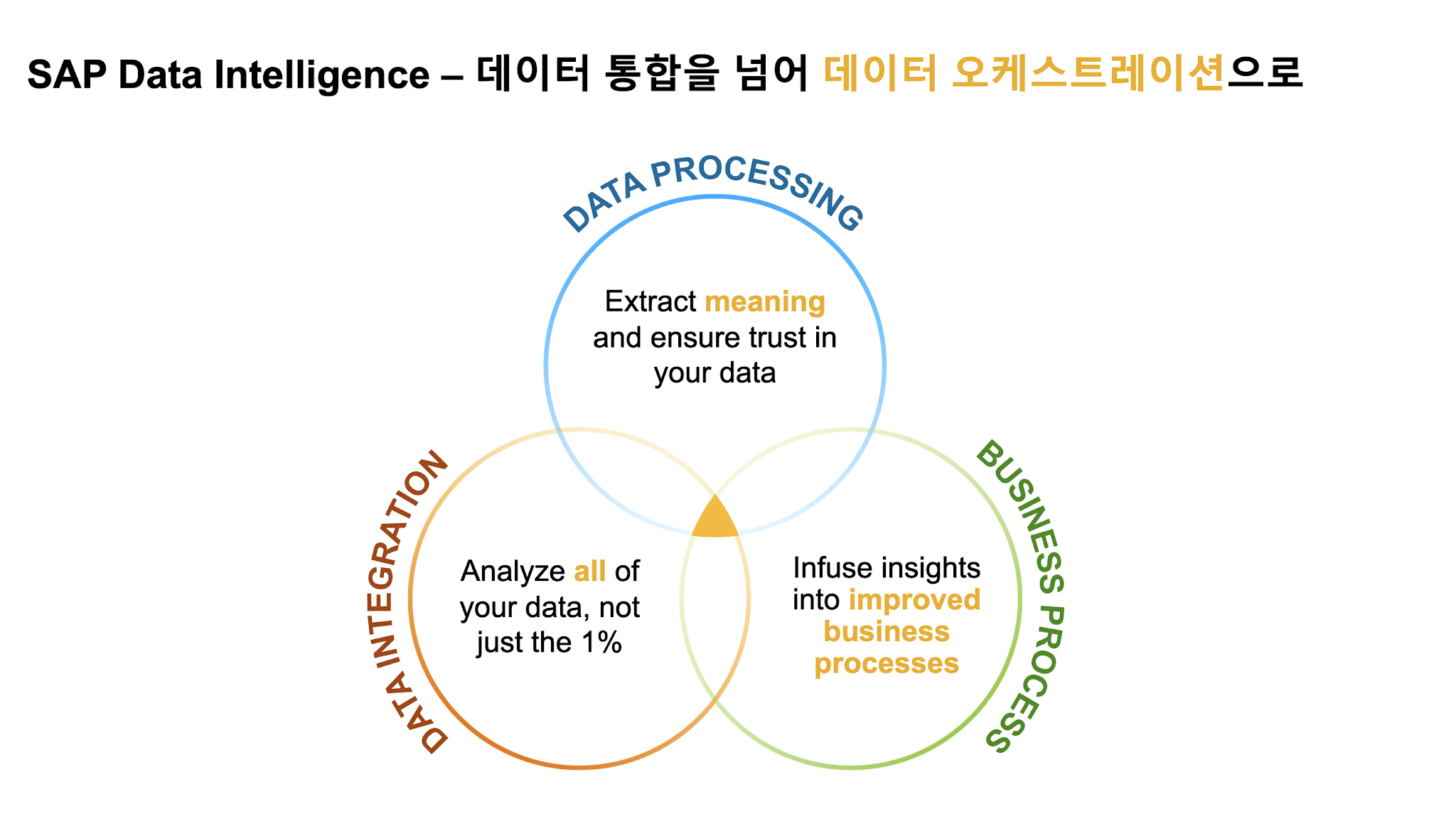
데이터 오케스트레이션 = 데이터 통합 + 데이터 처리(ML) + 자동화
SAP가 오픈 소스와 클라우드을 고려하고 처음부터 완전히 새로운 솔루션을 개발한 이유입니다.

ERP, BW 등 기존 기업 데이터는 그 동안 액세스, 통합 및 사용 등이 쉽지 않았던 스트림 데이터과 빅 데이터와 결합할 수 있는 가능성이 열렸습니다.
ML과 같은 데이터 처리 엔진을 적용하여 모든 데이터에 대한 포괄적인 액세스를 제공하고 결과를 비즈니스 프로세스 및 워크플로에 연결하면 진정한 데이터 오케스트레이션을 얻을 수 있습니다.
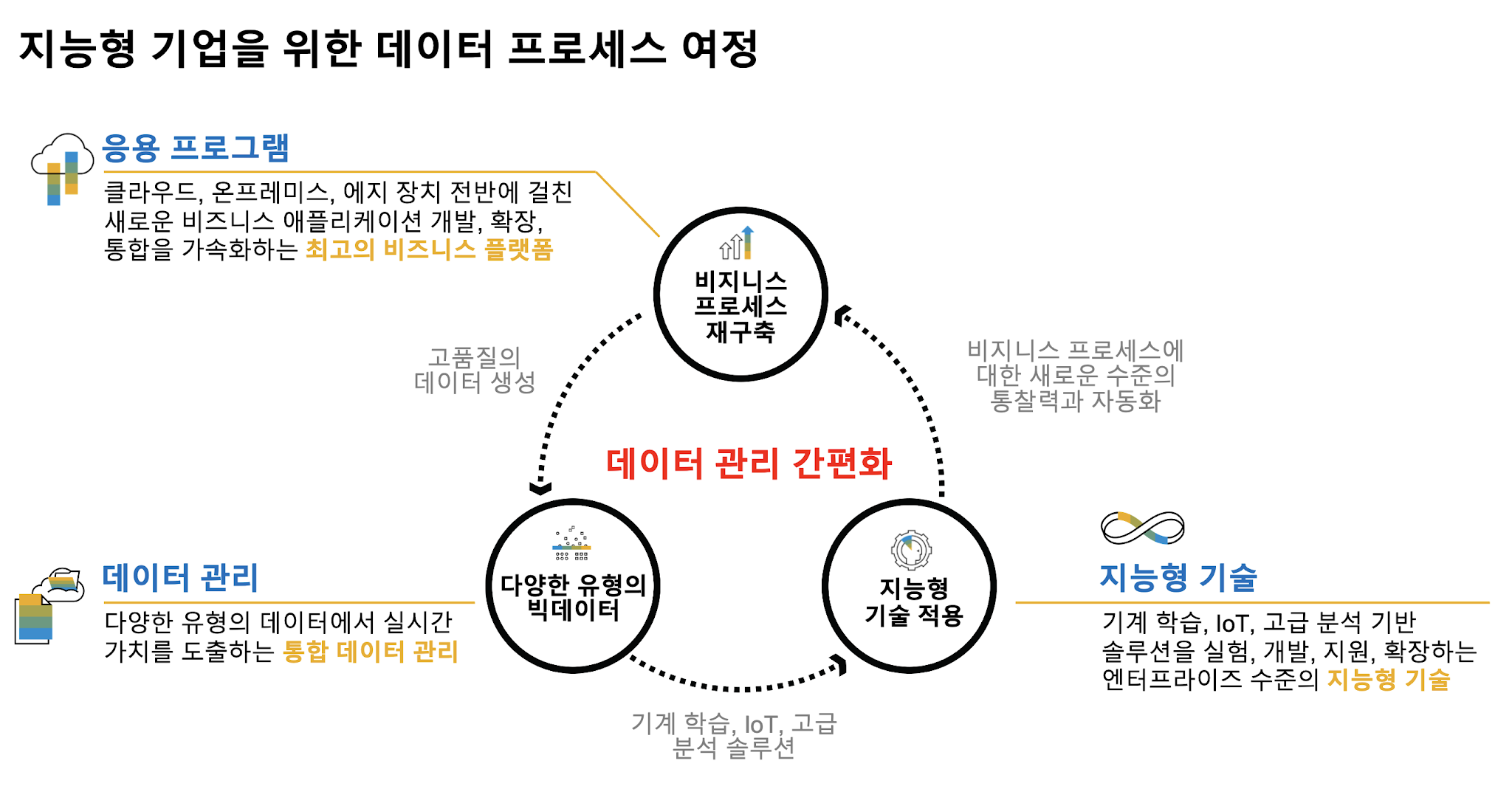
SAP Data Intelligence Cloud는 모든 조직이 데이터 및 비즈니스 프로세스를 오케스트레이션 및 자동화하는 동시에 기계 학습을 배포 및 운영할 수 있도록 설계되었습니다.
또한, 데이터 오케스트레이션을 통하여 데이터에서 가치를 추출하고 이를 민첩하고 재구성된 비즈니스 프로세스에 연결하는 방법을 제공 받습니다.

SAP Data Intelligence Cloud는 분산된 데이터 환경에서 복잡한 데이터 관리를 간소화하고 머신 러닝 구현과 운영을 신속하게 처리하여 지능형 통찰력으로 여러분의 업무 프로세스를 고도화합니다.